
Wird Cloud heutzutage überbewertet?
TL;DR - Cloud Computing ist oft eine Verschwendung; Unternehmen Deskillen sich selber; eine Abstraktionsschicht und gezielter Skillaufbau könnte der eine Weg sein.

Wird “die Cloud” überbewertet? Eine unbequeme Bilanz
Es gibt diesen Moment in fast jedem Budgetmeeting, in dem die Cloud‑Rechnung auf dem Tisch landet und niemand mehr weiß, warum sie schon wieder gestiegen ist. Wer als IT‑Entscheider die letzten zehn Jahre mitgegangen ist, hat den Erzählbogen verinnerlicht: „Cloud‑First” galt als Vernunftgebot und wer sich verweigerte, war Bedenkenträger. Aber es lohnt sich, diese Erzählung kühl zu prüfen.
Die Datenlage und ein wachsender Chor prominenter Praktiker legt eine andere These nahe: Cloud‑Provider und Managed Services werden systematisch überbewertet, ihre Vorteile stehen für viele Workloads in einem schlechten Preis‑Leistungs‑Verhältnis und der Preis dafür ist nicht nur monetär, sondern auch ein Verlust an betrieblicher Fähigkeit und Substanz.

27 Prozent Verschwendung sind kein Betriebsunfall
Die Zahlen aus dem Flexera State of the Cloud 2025/2026 sind ernüchternd: 27 bis 29 Prozent aller Cloud‑Ausgaben gelten als verschwendet, 84 Prozent der Unternehmen nennen das Cloud‑Kostenmanagement als ihre größte IT‑Herausforderung, und Budgets werden im Schnitt um 17 Prozent überschritten. Die FinOps Foundation, eigentlich eine Lobby‑Organisation der Cloud‑Optimierung, kommt zu ähnlichen Werten: Seit fünf Jahren stagniert die Quote zwischen 27 und 32 Prozent.
Stagnation ist hier das Signal. Diese Verschwendung ist strukturell, nicht zyklisch. Die IDC schätzt das globale Public‑Cloud‑Volumen 2024 auf 805 Milliarden Dollar mit Verdopplung bis 2028. Das hochgerechnete Verschwendungsvolumen liegt damit weltweit oberhalb von mindestens 200 Milliarden Dollar pro Jahr, Geld, das eben nicht in Innovation, Mitarbeiter oder Wettbewerbsfähigkeit fließt.
Wer glaubt, das sei ein Lückenproblem, das sich mit „etwas mehr FinOps” lösen lässt, sollte einen Blick auf die Margen werfen. Hyperscaler operieren mit operativen Margen von 30 bis 40 Prozent. Anders formuliert: Für jeden Euro Infrastruktur, den Sie konsumieren, zahlen Sie 30 bis 40 Cent Marge an Ihren Vermieter. Das ist ein legitimes Geschäftsmodell, aber es als „kosteneffizient” zu verkaufen, ist Marketing.
Die Repatriation‑Welle ist real aber differenziert
Fast jedem ist das Beispiel von 37signals bekannt. Diese senkten ihre Infrastrukturkosten von 3,2 Millionen auf 1,3 Millionen Dollar im Jahr, bei etwa 700 000 Dollar Einmalinvestition in eigene Server, die sich binnen eines Jahres amortisierte. Oft werden hier von Skeptikern Migrations- und Personalkosten noch ins Feld geführt. Ein offizielles Statement gibt es dazu nicht, jedoch Kommentare, dass dasselbe Team für Cloud und Applikation die Migration durchgeführt hat und weiterhin den Betrieb gewährleistet hat.
Dropbox sparte mit seiner Eigenbau‑Initiative „Magic Pocket” laut S‑1‑Filing rund 75 Millionen Dollar in zwei Jahren. GEICO stand 2021 bei über 300 Millionen Dollar Cloud‑Spend pro Jahr, einem 2,5‑fachen Budget‑Overrun, und reduziert seither über offene Hardware‑Standards die Compute‑Kosten pro Core um 50 Prozent.
Der Barclays CIO Survey Q4 2024 zeigt, dass 83 Prozent der CIOs zumindest einige Public‑Cloud‑Workloads zurück on‑prem oder in Private Clouds verlagern wollen. IDC beziffert für 2024 den Anteil der Unternehmen mit Repatriation‑Plänen auf rund 80 Prozent.
Wichtig für die Einordnung: Es geht nicht um den theatralischen Cloud‑Exit. Nur 8 bis 9 Prozent der Unternehmen planen Voll‑Repatriationen. Die Bewegung ist selektiv und ökonomisch motiviert, aber die Ergebnisse sprechen für sich.
Der unterschätzte Schaden: Verlust an Betriebskompetenz
Aber es wird noch unbequemer. Die Linux Foundation berichtet, dass 92 Prozent der Organisationen Schwierigkeiten haben, qualifizierte Cloud‑Talente zu finden. Mehr als 75 Prozent haben Projekte wegen Skill‑Lücken abgebrochen. Das Problem dahinter ist eines, über das in Vorstandsetagen ungern gesprochen wird: Eine ganze Engineering‑Generation hat schlicht nie ein Storage‑Tier dimensioniert, ein Netzwerk segmentiert oder eine Datenbank auf Bare‑Metal getunt. Wer „Cloud‑Native” gelernt hat, kann oft Terraform schreiben, aber keine echte Kapazitätsplanung machen. Und AI wird uns noch nicht davor retten.
Cloud‑Veteran David Linthicum bringt es auf den Punkt: Die durchschnittliche IT‑Abteilung habe gar nicht mehr das Engineering‑Talent, um größere Cloud‑Workloads zu repatriieren. Das ist die eigentliche Lock‑in‑Falle, nicht die proprietären APIs, sondern das organisationale Vergessen.
Verschärft wird das durch Outsourcing und Offshoring. Studien zeigen, dass 22 Prozent der Outsourcing‑Beziehungen binnen zwei Jahren scheitern, 48 Prozent spätestens in fünf, vorrangig wegen Qualitäts‑ und Kommunikationsproblemen. Was als Effizienzhebel verkauft wird, ist häufig ein systematischer Kompetenztransfer aus dem eigenen Haus und im schlimmsten Fall eine Erosion der Fähigkeit, Architekturentscheidungen überhaupt noch zu beurteilen. Offshore‑Modelle multiplizieren diesen Effekt durch Zeitzonen‑, Sprach‑ und Kulturfriktion und durch fluktuationsbedingten Wissensabfluss.
Meiner Meinung nach ist es eine absolute Vollkatastrophe, die von den meisten Unternehmen bewusst ignoriert wird.
Der Multi‑Cloud‑Sumpf
Wer geglaubt hat, Multi‑Cloud sei die Antwort auf Vendor‑Lock‑in, ist meist enttäuscht: 99 Prozent der Unternehmen berichten von Schwierigkeiten beim Multi‑Cloud‑Management; im Schnitt nutzen sie 2,4 Public‑Cloud‑Provider, 73 Prozent sagen, Cloud habe ihre Operations komplexer gemacht. Egress‑ und Inter‑Region‑Gebühren machen laut Gartner 10 bis 15 Prozent der Gesamtkosten aus und wirken als ökonomische Mauer zwischen den Anbietern. Multi‑Cloud ohne übergreifende Steuerung ist nicht Freiheit, sondern multiplizierte Komplexität.
Übrigens sind hier europäische Anbieter in der Regel praktikabler, da sie selten Egress-Kosten verrechnen.
Die Lösung: Provider zur API degradieren
Die strategische Antwort liegt nicht im Schwarz‑Weiß‑Denken („alles raus” vs. „alles rein”), sondern in einer eigenen Plattform‑Schicht über den Cloud‑Providern. Konzeptionell bedeutet das:
Provider = austauschbarer Infrastruktur‑Lieferant. Compute, Storage, Netzwerk und GPUs werden konsumiert wie Strom, in der Region, beim Anbieter und zur Tageszeit, an dem sie am günstigsten oder geeignetsten sind. Die Preisspreizung macht das ökonomisch zwingend: Bei aktuellen GPU‑Pricing‑Vergleichen liegen H100‑Stundenraten je nach Provider zwischen rund 0,47 und über 14 US‑Dollar pro GPU‑Stunde. Wer hier statisch einkauft, verschenkt Faktoren, nicht Prozente.
Eine Abstraktionsschicht. Konzeptionell ein „Supercloud”‑ oder Plattform‑Engineering‑Layer, kapselt provider‑spezifische APIs, vereinheitlicht Identity, Policies, Observability und Deployment‑Pipelines. Gartner prognostiziert, dass bis 2026 80 Prozent der großen Engineering‑Organisationen eigene Plattform‑Teams aufbauen werden. Das ist kein Hype, sondern eine Konsequenz aus der gelebten Komplexität.
Agentenbasierte Architektur‑Empfehlungen sind das nächste “künstliche” Glied: Multi‑Agent‑Systeme, die fortlaufend Kosten‑, Performance‑, Latenz‑ und Compliance‑Daten konsolidieren und Vorschläge machen, welcher Workload wohin gehört, idealerweise mit nachvollziehbarer Begründung statt Black‑Box‑Empfehlung.
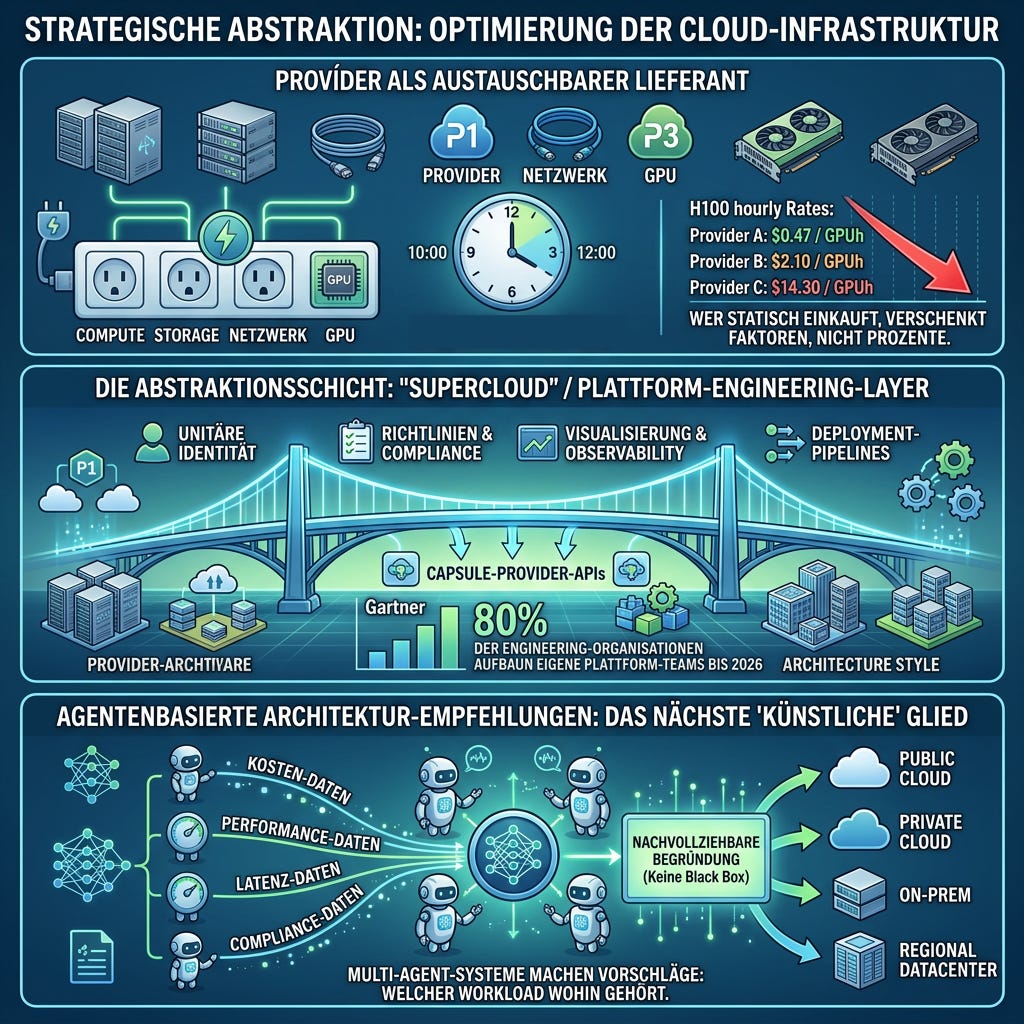
Was IT‑Entscheider in Betracht ziehen sollten
Drei Konsequenzen, die sich aus der Datenlage ableiten:
Erstens: Operations‑Kompetenz wieder ins Haus holen. Ein eigener Plattform‑Layer braucht echte Engineers, die Hardware, Netzwerk, Storage und Workload‑Ökonomie verstehen. Das ist teuer, aber 27 Prozent verschwendete Cloud‑Ausgaben sind teurer.
Zweitens: Cloud strategisch nutzen, nicht religiös. Cloud bleibt brillant für Lastspitzen, schnelle Experimente und Greenfield‑Projekte, in denen Time‑to‑Market regiert. Sie ist aber typischerweise das schlechteste Modell für vorhersehbare, datenintensive, dauerlaufende Workloads. Kostentechnisch. Und Enterprises reitzen regelmäßig die Standardservices von Providern aus, sodass diese selbst gebaut werden müssen. Genau dort liegen die Repatriation‑Cases.
Drittens: In eine Abstraktionsschicht investieren. Wer seine Workloads so kapselt, dass sie ohne Architektur‑Rewrite zwischen Providern aber auch zu eigener Hardware wandern können, gewinnt sowohl Verhandlungsmacht als auch Resilienz. Das ist die einzig nachhaltige Antwort auf Egress‑Fees, Vendor‑Lock‑in und unkontrollierte Margen. Und vermutlich einer der wenigen Schritte in Richtung Souveränität.
Ich muss aber auch betonen, dass “die Cloud” nicht das Problem ist. Wer sie als das behandelt, was sie wirklich ist, ein Infrastruktur‑Lieferant unter mehreren, baut eine IT, die wieder beweglich, kompetent und wirtschaftlich gesund ist. Genau das ist heute der eigentliche Wettbewerbsvorteil.
Caveats zur Quellenlage
Die 83‑%‑Repatriation‑Zahl (Barclays CIO Survey) wird von Channelnomics u. a. relativiert: Sie misst Unternehmen, die irgendeinen Workload zurückholen, nicht das Volumen. Die Aussagekraft ist eingeschränkt; richtig ist aber, dass Repatriation ein Trend, kein Massenexodus ist (IDC: nur 8–9 % Voll‑Repatriation).
Einige der Repatriation‑Erfolgszahlen (37signals, Dropbox) stammen aus Selbstauskünften der Unternehmen bzw. SEC‑Filings. Sie sind plausibel, aber nicht unabhängig auditiert. 37signals selbst weist darauf hin, dass die Rechnung nicht 100 % apples‑to‑apples ist (Hardware‑Refresh, Power, Cooling werden je nach Berechnung mit/ohne berücksichtigt).
Andrew Tanenbaum ist nicht primär ein Cloud‑Kritiker; seine Bekanntheit stammt aus der Linux‑Microkernel‑Debatte 1992. Im Artikel wurde er bewusst nicht als Cloud‑Kritiker zitiert. Wer eine akademisch fundierte Cloud‑Skepsis sucht, findet sie eher bei Bryan Ford (Yale, „Icebergs in the Clouds”).
Die GPU‑Preise sind volatil; insbesondere H100‑Spot‑/Marketplace‑Preise schwanken stark. Der Punkt, mehrfache Preisspreizung zwischen Anbietern, bleibt aber stabil.
Der „Supercloud”-Begriff ist konzeptionell, nicht standardisiert. Manche nennen es auch Sky Computing. Im Artikel wurde er deshalb umschrieben und nicht als Produktkategorie verwendet. Ich persönlich würde eher für eigens gebaute Platform-of-Platforms Ansätze plädieren.
Cloud‑Waste‑Quoten variieren je nach Studie zwischen 21 % (Harness, eng definiert) und bis zu 47 % (manche Surveys, weit definiert). Die genannte Spanne 27–32 % ist der robuste Median über Flexera, FinOps Foundation und Datadog hinweg.